

과제
더핑크퐁컴퍼니는 “아이의 세상 모든 첫 경험을 즐겁게” 라는 슬로건 아래 아기상어, 베베핀 등의 유아동 콘텐츠를 만들고 서비스하는 회사입니다. 주로 유튜브와 같은 동영상 플랫폼을 통해 콘텐츠를 유통하지만, 장편 애니메이션이나 뮤지컬 공연, 완구 상품, 모바일 앱 등 다양한 형태로 고객과 접점을 가지고 있습니다.
이번 하루개발에서는 10여년 전, 개발에 직접 참여했던 오래된 레거시 서비스와 서버들을 확인하고 정리하는 업무를 맡았습니다.
해결 과정
대부분의 백엔드 서비스는 재직하던 시절에 이미 Docker 이미지로 제작해 AWS ECS로 서비스되고 있었습니다. 하지만 과거에 사용하던 온-프레미스 서버 일부가 남아있어, 외부 IDC 업체의 서버 호스팅을 사용하고 있습니다. 여러가지 이유로 제가 담당하지 않은 이후 10여년 이상 당시 상태 그대로 서비스되고 있었습니다.
- 안-정적인 모바일 서비스 만들기, 2014
- Django in Production, 2015
우선 웹 서버로 사용 중이었던 Nginx의 로그와 MySQL, MongoDB 등 데이터베이스의 상태부터 확인하였습니다.
앱 정보 정리
과거에 서비스했던 모바일 앱들 중 일부가 여전히 예전 도메인으로 접속해 초기 데이터를 받아가고 있음을 확인하고, 도메인의 라우팅 정보를 수정하는 것만으로 문제를 일부 해결하였습니다. 해당 과정에서 더 이상 서비스하지 않는 200여개 앱의 정보를 확인해 관리 및 로그 수집에서 효율성을 높였습니다.
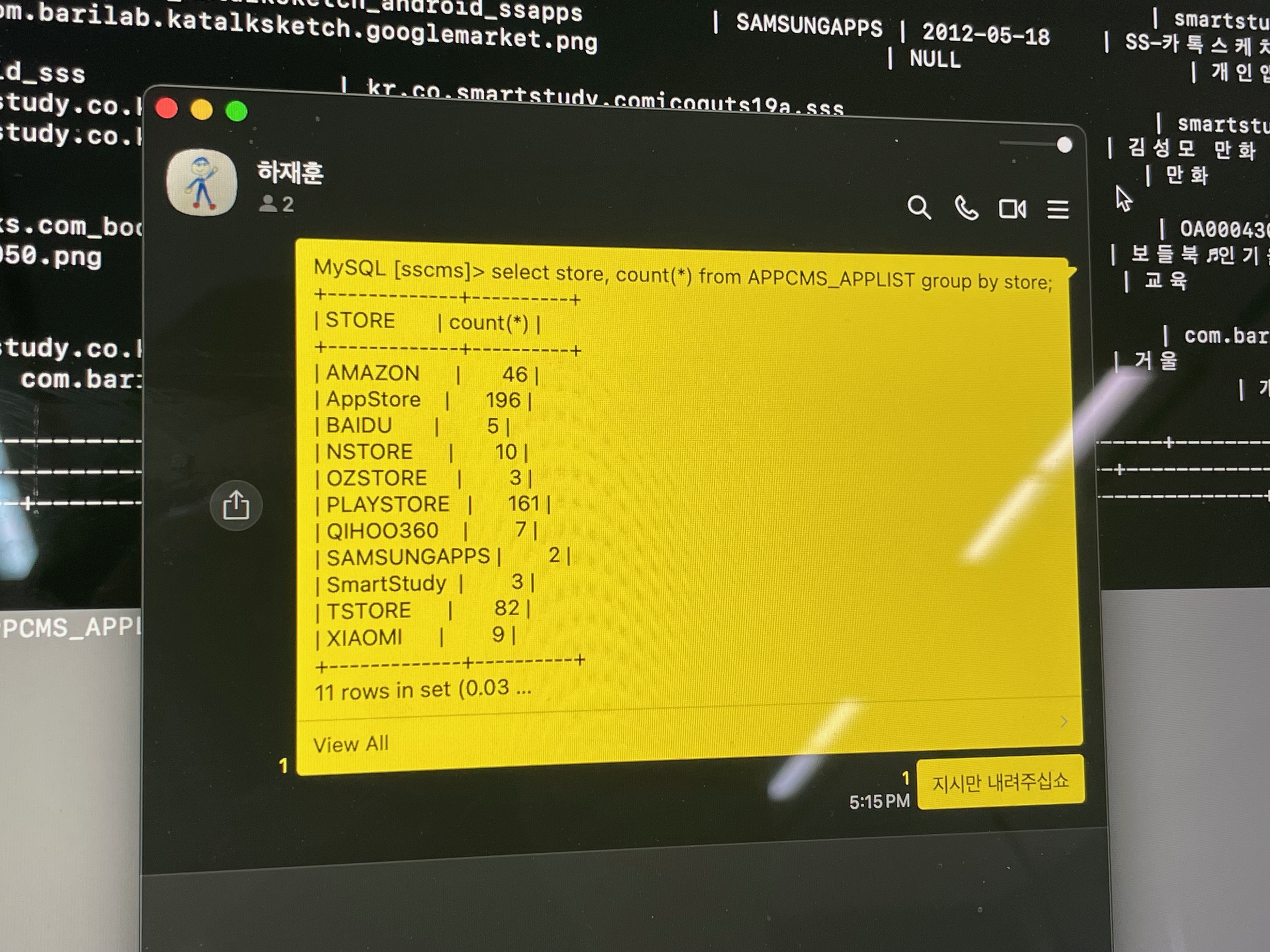
스토어별 서비스했던 앱 목록 추출
API 서비스/서버 정리
같은 형태로 AWS에도 존재하는 중복된 API 서비스들이 있어, 데이터를 확인하고 도메인 정보만 변경해 문제를 해결할 수 있는지 알아보았습니다. 일부 불일치하는 데이터가 있음을 확인했으나 이관 또는 병합할 필요성까지는 없다고 판단한 서비스도 있었고, 필요한 경우 AWS Lambda와 API Gateway 조합으로 기능을 이전했습니다.
온-프레미스 장비 외에도 CloudWatch 로그를 보며, 사용하지 않는 채로 방치된 여러 EC2 인스턴스들을 제거했습니다.
로그 서비스 마이그레이션
과거 직접 조립한 하드웨어에서 Redis, MongoDB, 그리고 Django의 조합으로 만들었던 로그 수집/분석 시스템이 역시 10년 이상 예전 상태 그대로 서비스되고 있었습니다. 로그 수집과 분석에 Snowflake나 Retool 등을 새로 도입하기도 했지만, 모바일 앱들의 로그 분석은 여전히 이 시스템에 의존적인 상태였습니다.
- Redis, MongoDB 그리고 MySQL 과 함께하는 모바일 애플리케이션 서비스에서의 로그 수집과 분석, 2012
- The MongoDB Strikes Back / MongoDB 의 역습, 2013
JSON 형태의 100억 건 이상의 로그가 기존 로그 시스템과 Snowflake에 이중으로 저장되어 있었습니다. 과거 MongoDB Aggregation과 파이썬 코드를 통해 분석하던 정보를 Snowflake의 Aggregate Functions 로 바꿔야 했습니다.
이를 위해 기존 시스템처럼 JSON 그대로 저장되어 있던 값을 파싱해 쿼리에서 사용할 수 있도록 변환해야 했고, 동시에 시계열 데이터 분석의 특성을 고려해 특정 값 단위로 클러스터링할 필요가 있습니다. 또한, 이제까지와 마찬가지로 로그를 남기는 주체마다 서로 다른 키/값 들을 가질 수 있으므로, 로그 원본은 여전히 JSON 형태를 유지해야 했습니다.
로그 원본 테이블을 대상으로 바로 통계 쿼리를 실행할 수 없으므로, 다음과 같은 순서로 작업했습니다.
- 수집기에서 수집한 JSON 형태 그대로 Snowflake의 테이블에 로그를 저장합니다.
PARSE_JSON함수를 이용해 로그의 키를 컬럼 단위로 분리한 Materialized View를 생성합니다.- 최적화된 분석을 위해 로거 아이디, 이벤트 타입, 로그 기록 시각의 세 컬럼을 이용해 클러스터링된 테이블을 최종적으로 생성합니다.
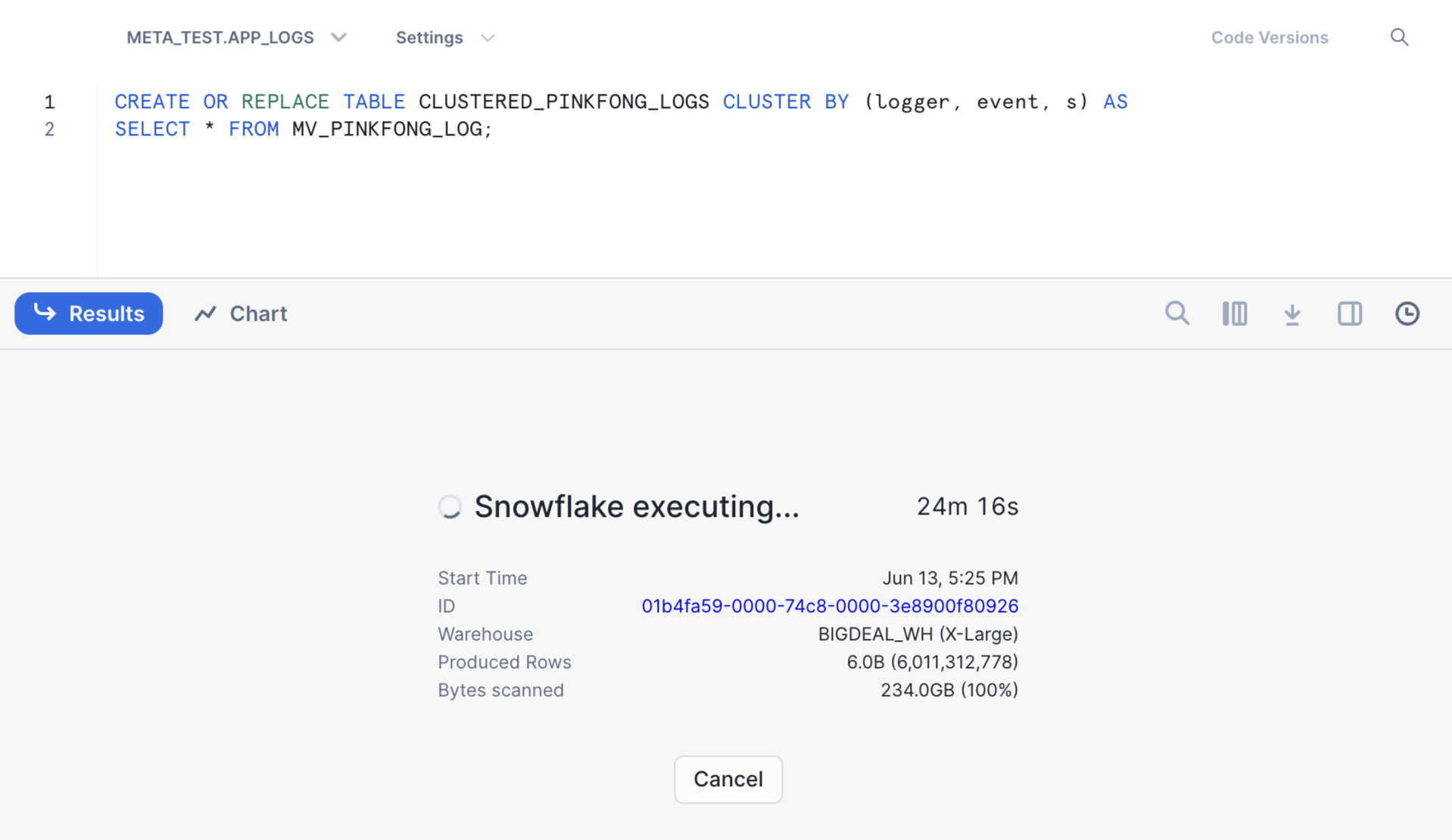
최적화된 분석을 위해 클러스터링된 테이블을 생성
이미 저장되어 있는 로그의 숫자가 많고 용량이 제법 크다 보니 각 과정을 수행할 때마다 많은 시간이 소요되었습니다. 작업 수행 시간을 예상하는 일에도 ChatGPT가 많은 도움이 되었습니다. 시간 관계상 기존 서비스를 완전히 내리진 못하고, 클러스터링 테이블을 생성하고 기존 MongoDB의 쿼리를 Snowflake에서 어떻게 바꿔 수행해야 할지 예제 코드를 제공하는 데 그쳤습니다.
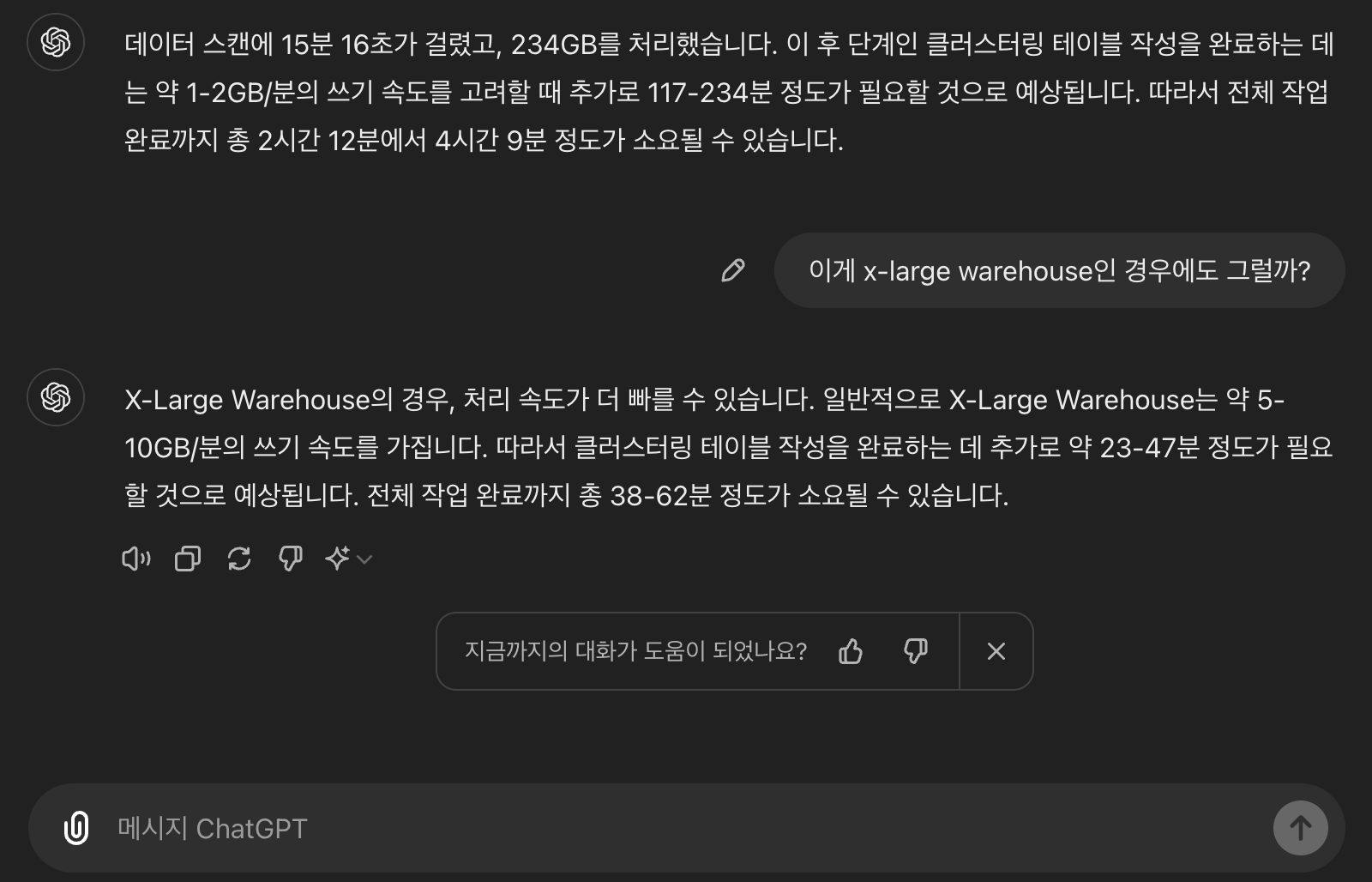
ChatGPT를 이용해 Snowflake 작업 수행 시간을 예상하기
여담
Nginx ghost request
온-프레미스 서버의 로그를 tail -f로 모니터링 하고 있는데, 특정 API 요청이 AWS로 바로 가는 것이 아니라, 이 서버의 Nginx를 거쳐 불필요하게 리디렉션되고 있어 경유하지 않도록 라우팅 설정을 변경하였습니다.
변경 사항이 다른 네임서버들에게 전파되는데 필요한 몇백초 정도의 TTL을 기다리며 모니터링을 계속하고 있는데, tail 결과로는 더 이상 클라이언트들로부터 요청이 오지 않음에도 불구하고 여전히 온-프레미스 서버로부터의 리디렉션이 발생하고 있었습니다. 서버 하드웨어 뿐만 아니라 Nginx 자체도 재시작 없이 4천일 이상 동작하고 있었기에 어떤 일이 발생해도 이상하지는 않았습니다만, 별도의 설정 변경 없이 Nginx 서버를 재시작하는 것만으로 마치 귀신처럼 보이던 요청이 사라졌습니다.
Snowflake clustered table
일반적인 RDB의 경우, 멀티 컬럼 인덱스를 설정할 때 키의 순서가 중요합니다. 예를 들어 이번과 같이 (logger, event, ...) 순서로 키를 지정하면 앞 조건부터 모두 일치하는 경우에만 인덱스 사용이 가능합니다. 즉, logger를 지정하지 않고 WHERE event = 'click'과 같이 쿼리하는 경우에는 인덱싱 효과를 누리기 어렵습니다.
- 참고: Optimzation and Indexes: Multiple-Column Indexes, MySQL Docs
그래서 여러 순서를 가진 인덱스를 생성하거나 아예 서로 다른 클러스터 키를 가진 테이블에 중복쓰기를 시도한 경우도 있었는데, Snowflake의 경우 기본적으로 마이크로 파티셔닝이 잘 지원되기도 하지만, 키 순서와 무관하게 예상했던 것보다 빠른 탐색을 할 수 있어 놀랐습니다. 문서를 좀 더 꼼꼼히 읽고 클러스터 키를 지정하는 과정에서 로그 기록 시간 컬럼에 TO_DATE 등의 함수를 이용해 카디널리티를 개선했으면 더 좋았을 것 같습니다.
- 참고: 클러스터링 키 및 클러스터링된 테이블, Snowflake Documentation

